Multi-Cue Guided Semi-Supervised Learning
toward Target Speaker Separation in Real Environments
Authors: Jiaming Xu, Jian Cui, Yunzhe Hao, Bo Xu
Abstract: To solve the cocktail party problem in real multi talker environments, this paper proposed a multi-cue guided semi-supervised target speaker separation method (MuSS). Our MuSS integrates three target speaker-related cues, including spatial, visual, and voiceprint cues. Under the guidance of the cues, the target speaker is separated into a predefined output channel, and the interfering sources are separated into other output channels with the optimal permutation. Both synthetic mixtures and real mixtures are utilized for semi-supervised training. Specifically, for synthetic mixtures, the separated target source and other separated interfering sources are trained to reconstruct the ground-truth references, while for real mixtures, the mixture of two real mixtures is fed into our separation model, and the separated sources are remixed to reconstruct the two real mixtures. Besides, in order to facilitate finetuning and evaluating the estimated source on real mixtures, we introduce a real multi-modal speech separation dataset, RealMuSS, which is collected in real-world scenarios and is comprised of more than one hundred hours of multi-talker mixtures with high-quality pseudo references of the target speakers. Experimental results show that the pseudo references effectively improve the finetuning efficiency and successfully evaluate the estimated speech on real mixtures, and various cue-driven separation models are greatly improved in signal-to-noise ratio and speech recognition accuracy under our semi-supervised learning framework.
Our Proposed Method
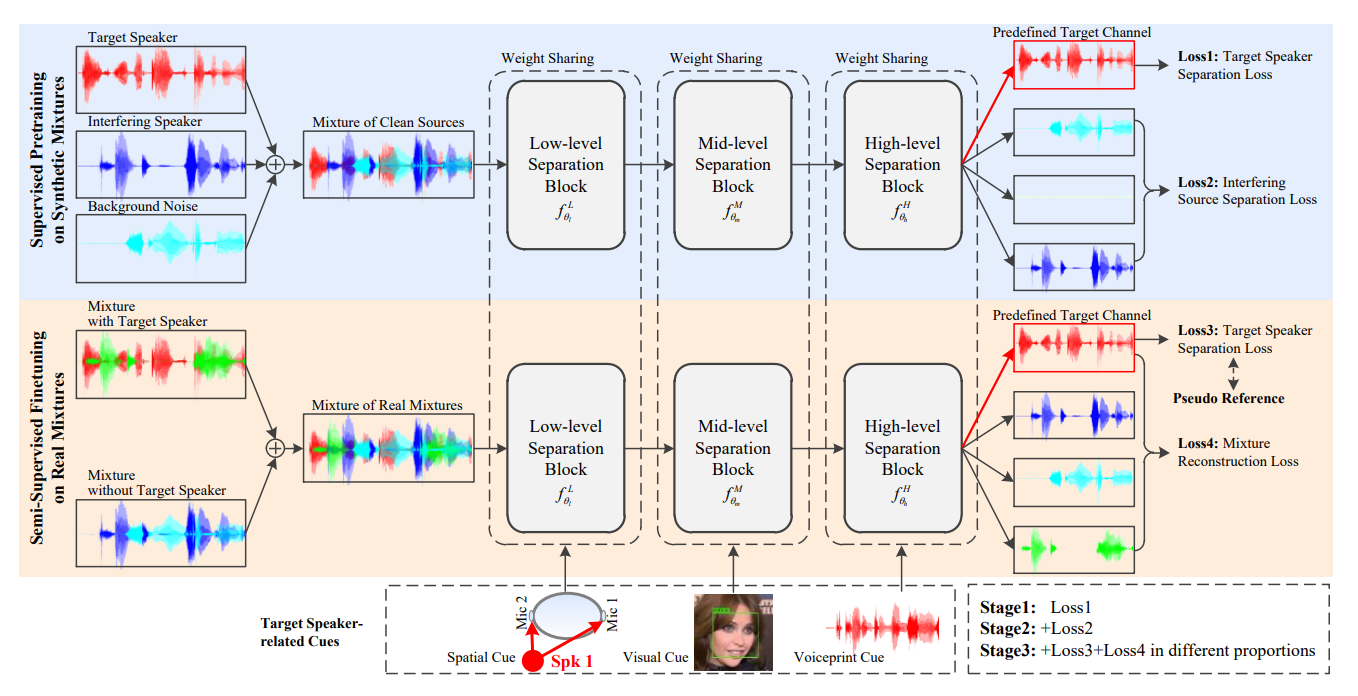
The figure below is our proposed multi-cue guided semi-supervised target speaker separation architecture. The separation model is guided by three speaker-related cues including spatial, visual and voiceprint cues. The training procedure is divided into three stages, where Stage 1 and Stage 2 are supervised learning on synthetic mixtures, and Stage 3 is semi-supervised learning on real mixtures. In Stage 3, different proportions of pseudo references would be fed to finetune the target source.
Demos (See More Samples)
Description: There are 15 models in total, including our MuSS with 10 possible cue combinations, and 5 baseline models. The predicted wavforms and evaluations in WER (%) and SI-SDR (dB) of English and Mandarin mixtures are as follows:
Note: VP: Voiceprint Cue VIS: Visual Cue SP: Spatial Cue BI: Binaural Input

SCENARIO ONE
SCENARIO TWO
SCENARIO THREE
MIXTURE
(WER: 160%; SI-SDR: 2.35)
(WER: 62.5%; SI-SDR: 3.44)
(WER: 310%; SI-SDR: -0.56)
PSEUDO REFERENCE
(WER: 0%; SI-SDR:/)
(WER: 0%; SI-SDR:/)
(WER: 0%; SI-SDR:/)
Our MuSS with BI-SP-VIS-VP
(WER: 0%; SI-SDR: 20.39)
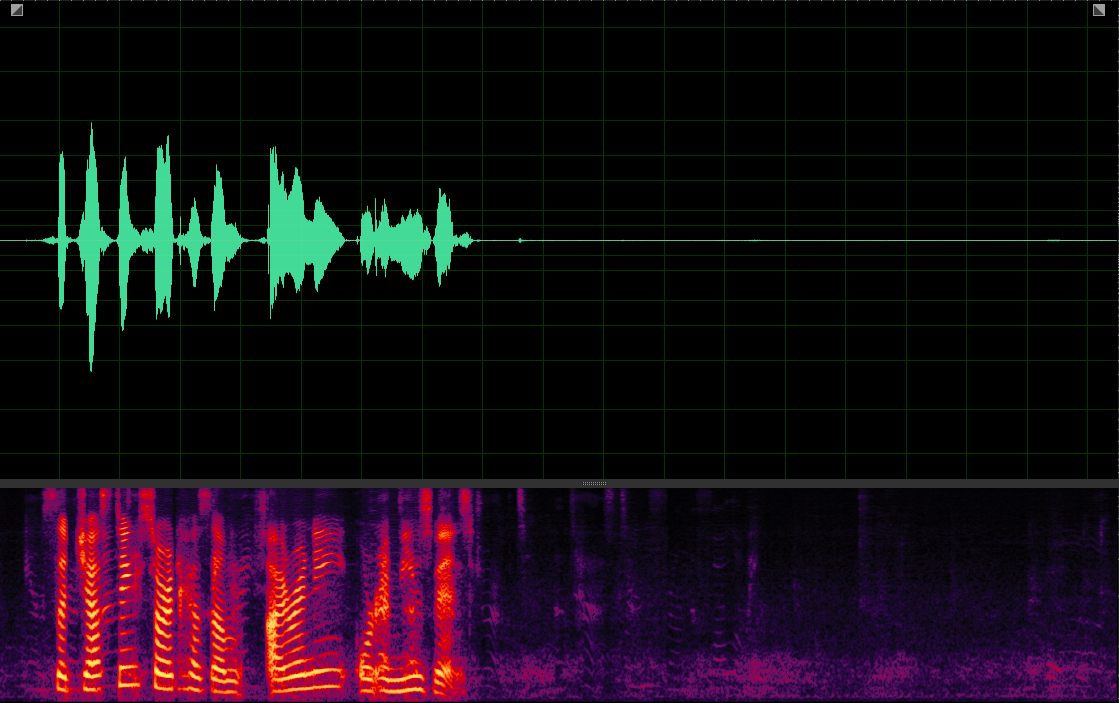
(WER: 0%; SI-SDR: 16.76)
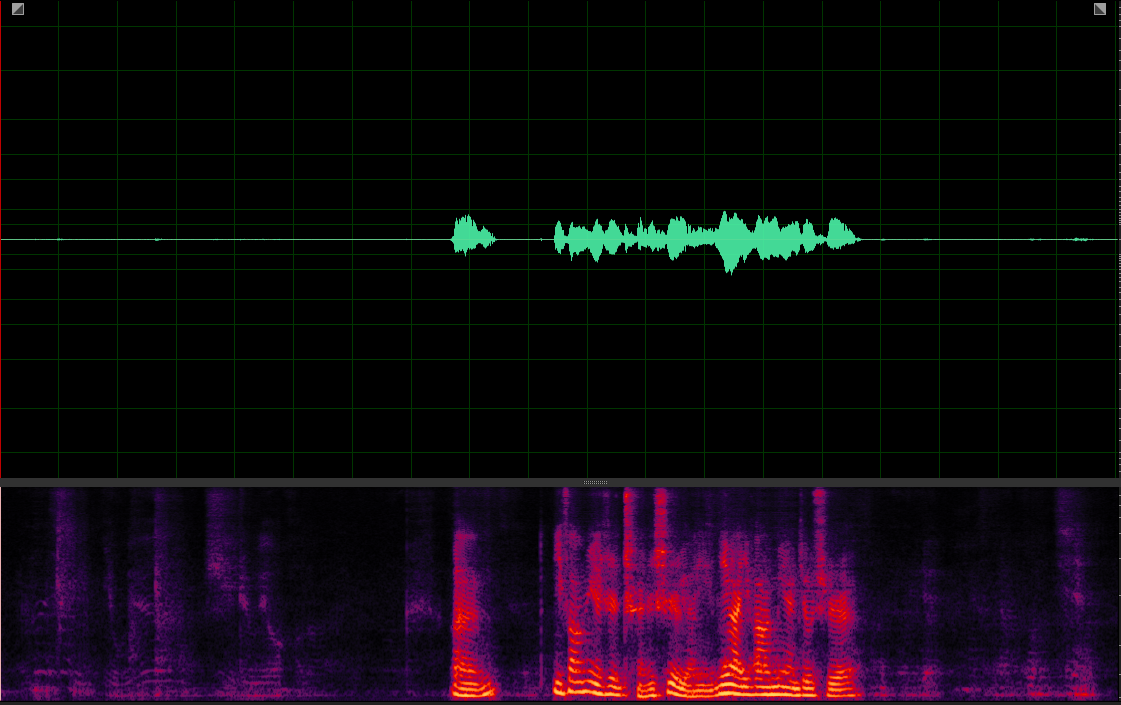
(WER: 0%; SI-SDR: 9.81)
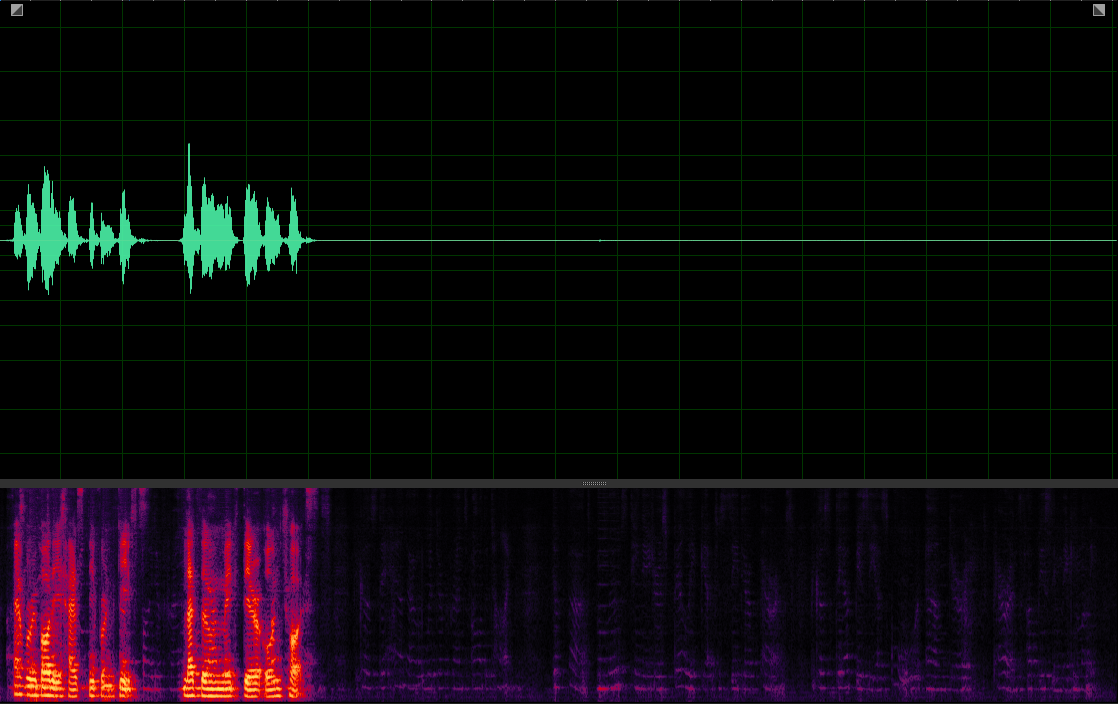
Our MuSS with BI-SP-VIS
(WER: 0%; SI-SDR: 19.94)
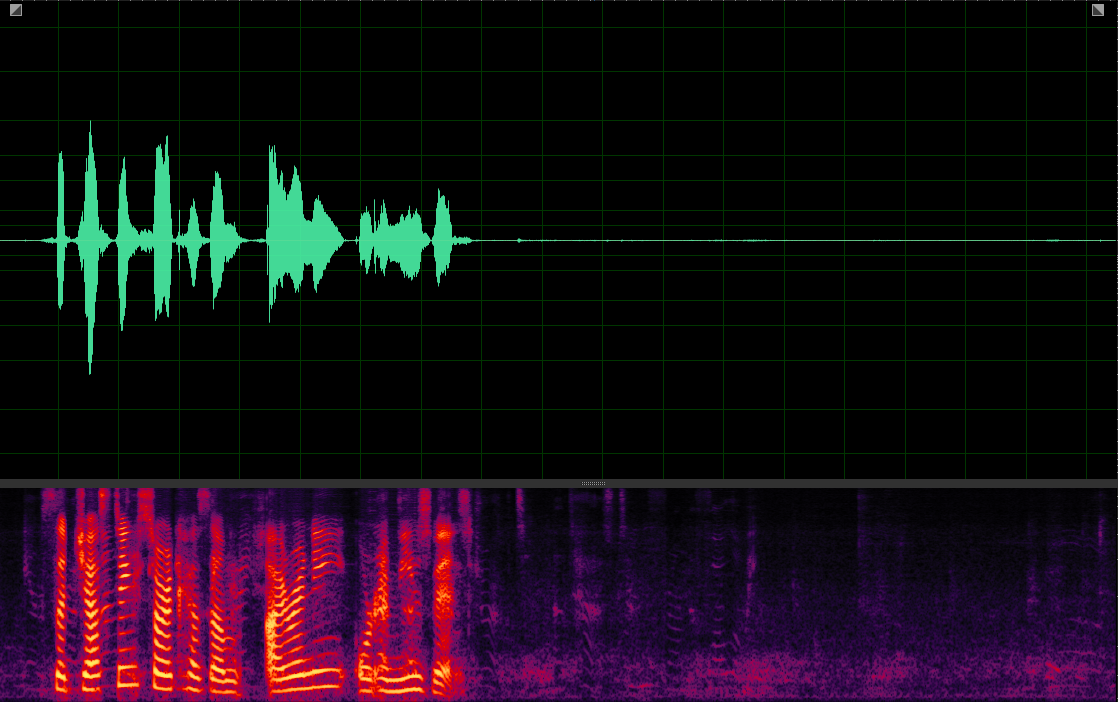
(WER: 6.25%; SI-SDR: 16.8)
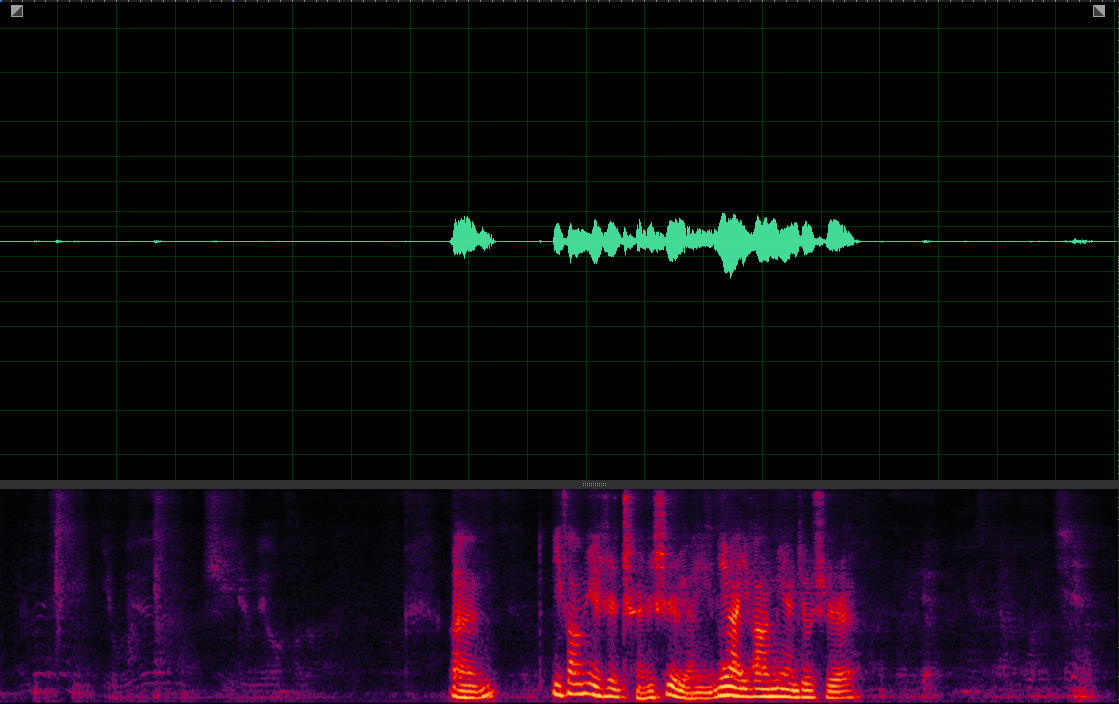
(WER: 340%; SI-SDR: -3.27)
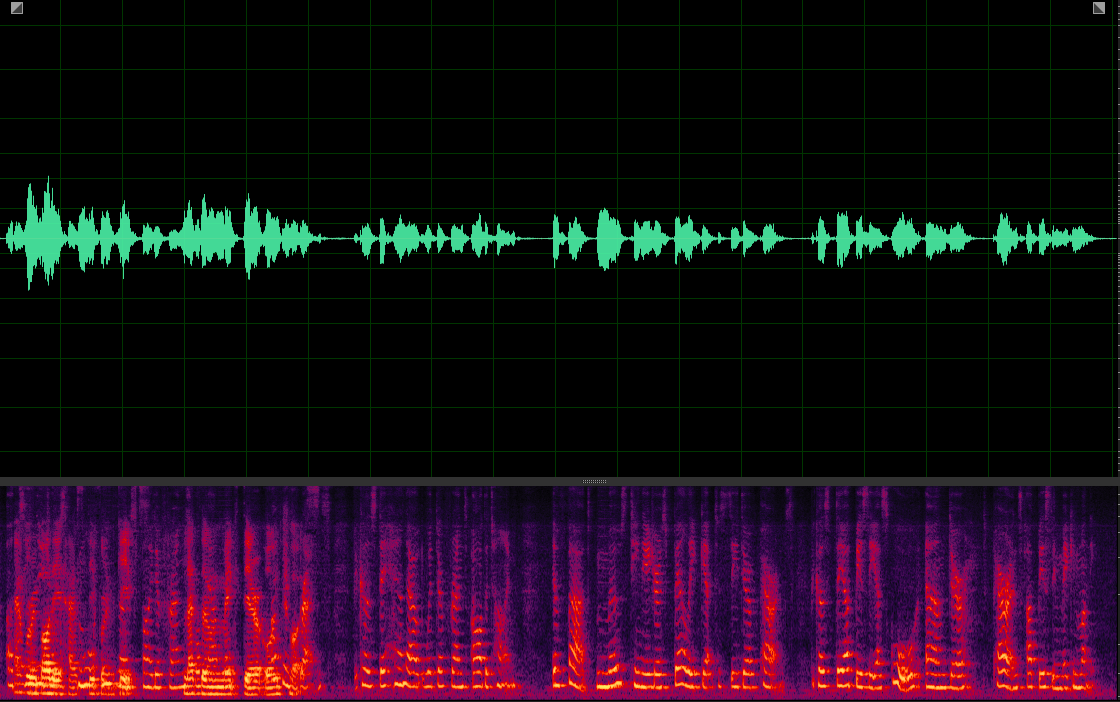
Our MuSS with BI-SP-VP
(WER: 0%; SI-SDR: 19.32)
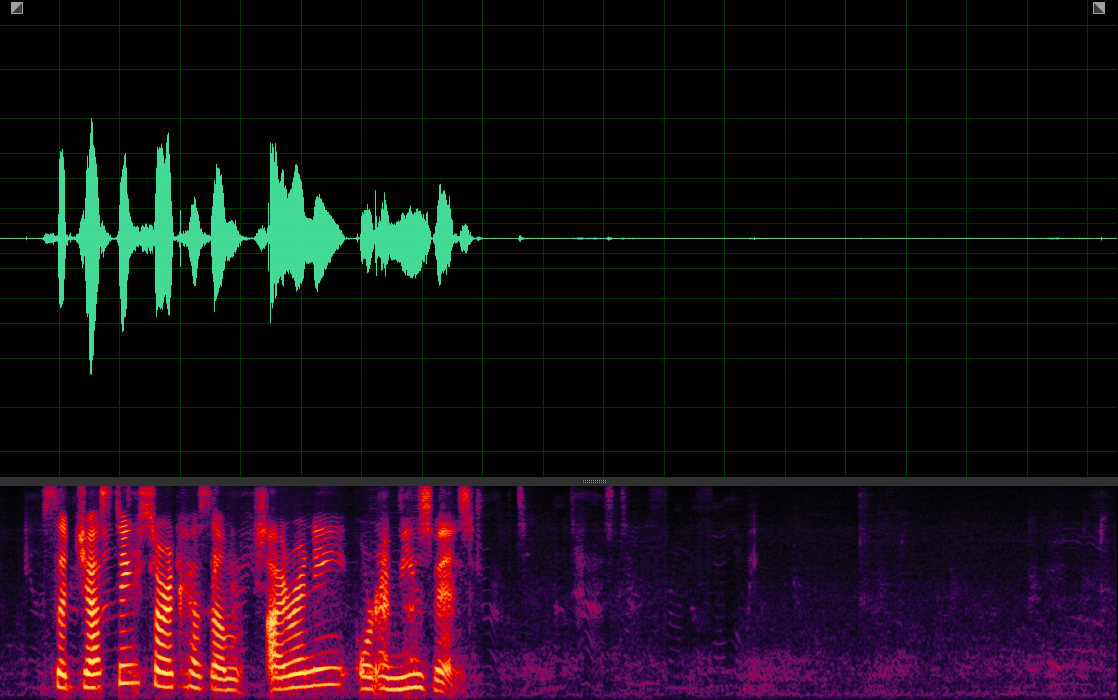
(WER: 6.25%; SI-SDR: 15.51)
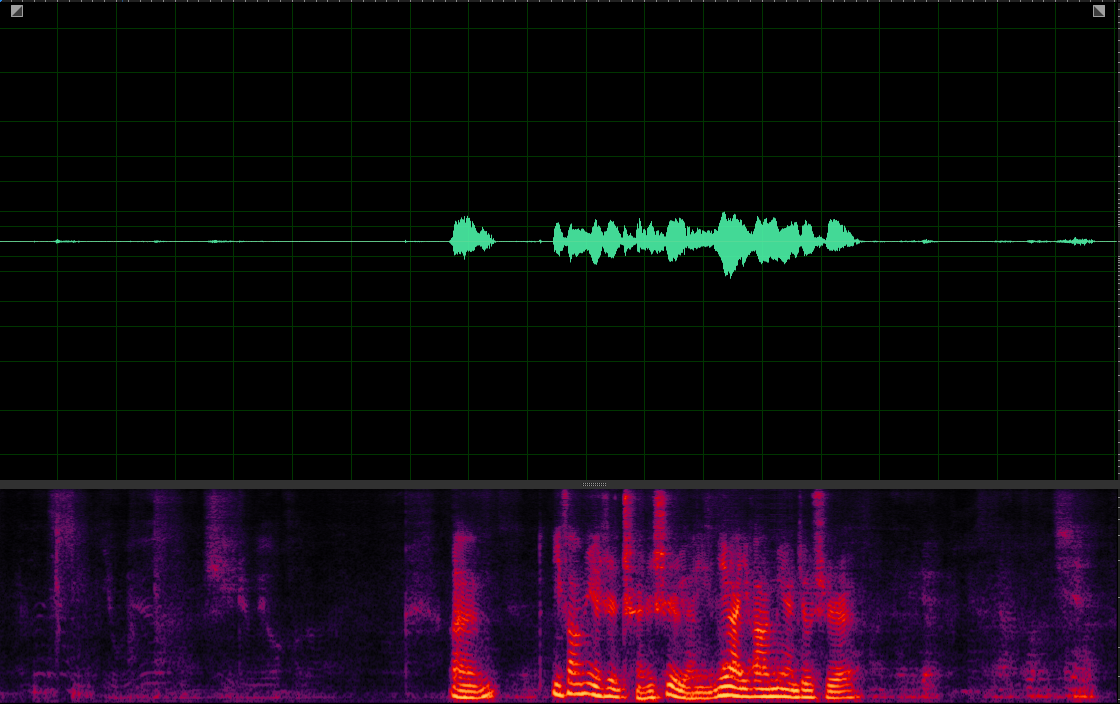
(WER: 0%; SI-SDR: 13.38)
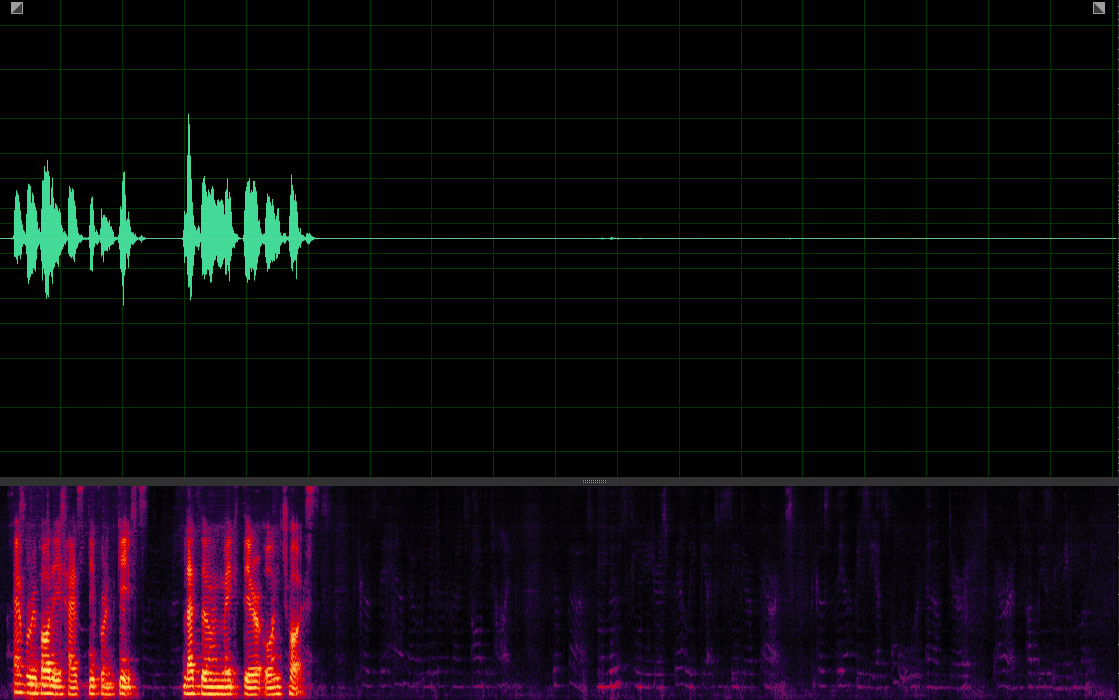
Our MuSS with BI-SP
(WER: 0%; SI-SDR: 19.16)
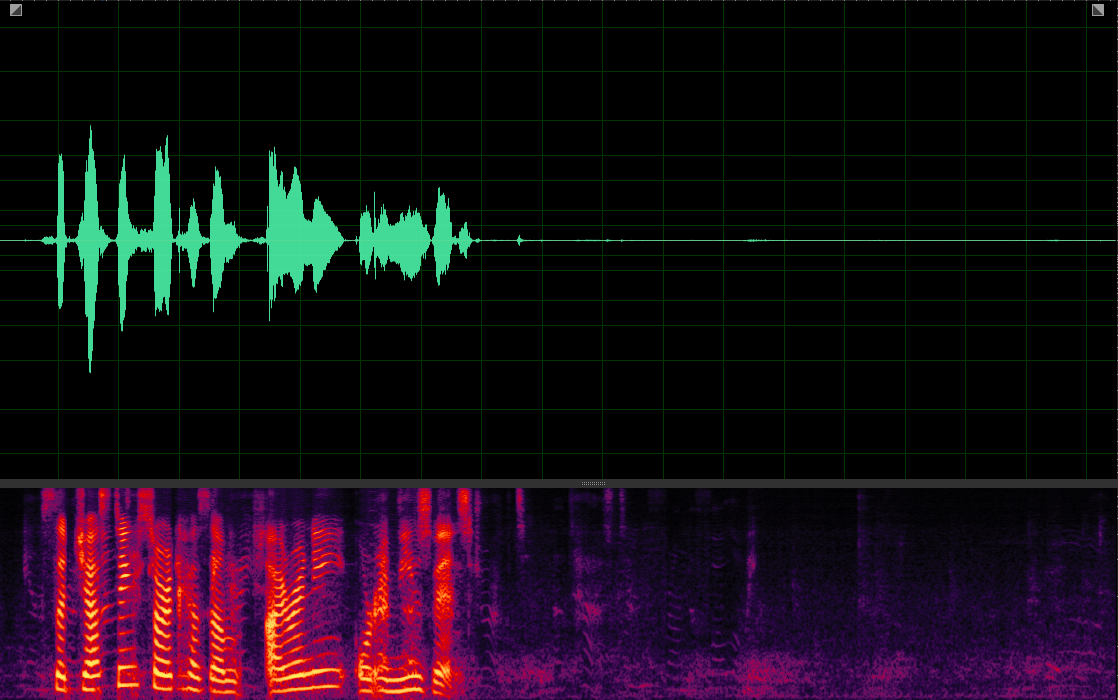
(WER: 6.25%; SI-SDR: 16.27)
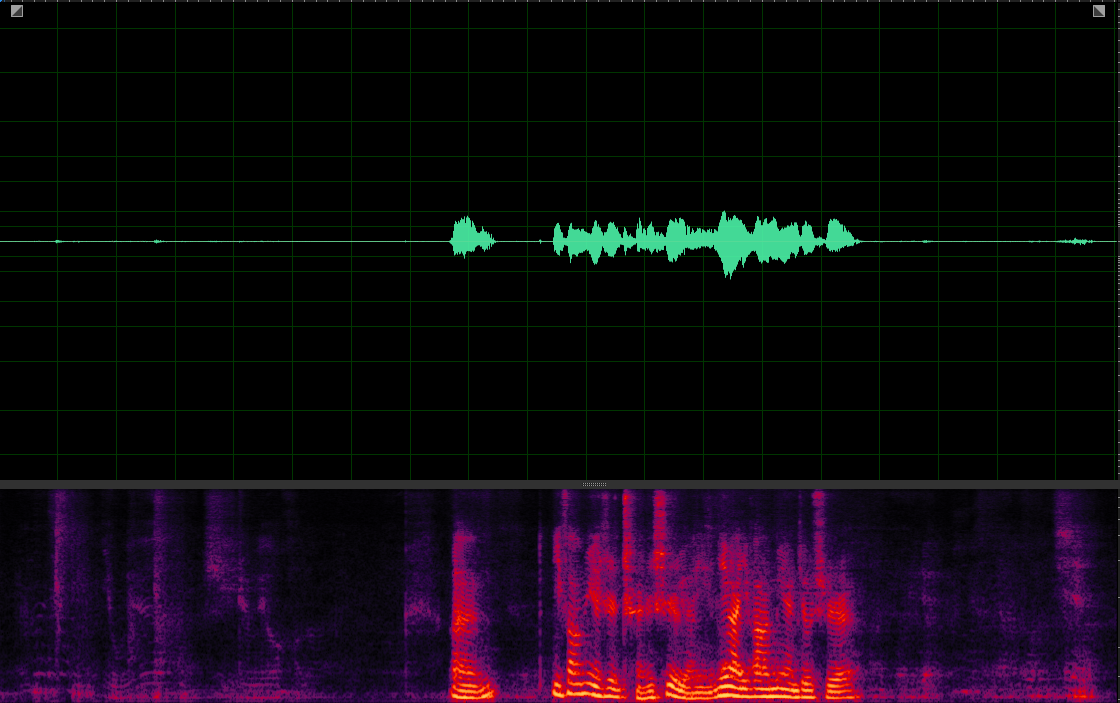
(WER: 350%; SI-SDR: -16.99)
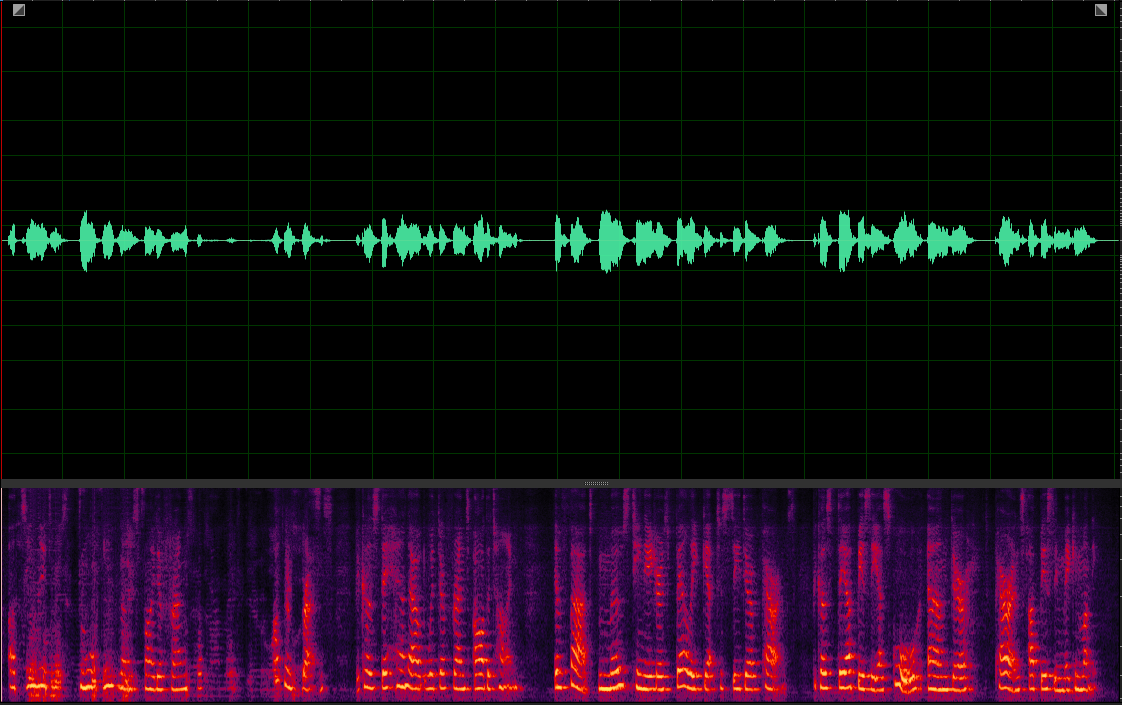
Our MuSS with BI-VIS-VP
(WER: 0%; SI-SDR: 17.68)
(WER: 0%; SI-SDR: 16.25)
(WER: 0%; SI-SDR: 16.33)
Our MuSS with BI-VIS
(WER: 0%; SI-SDR: 18.98)
(WER: 6.25%; SI-SDR: 17.22)

(WER: 0%; SI-SDR: 15.38)
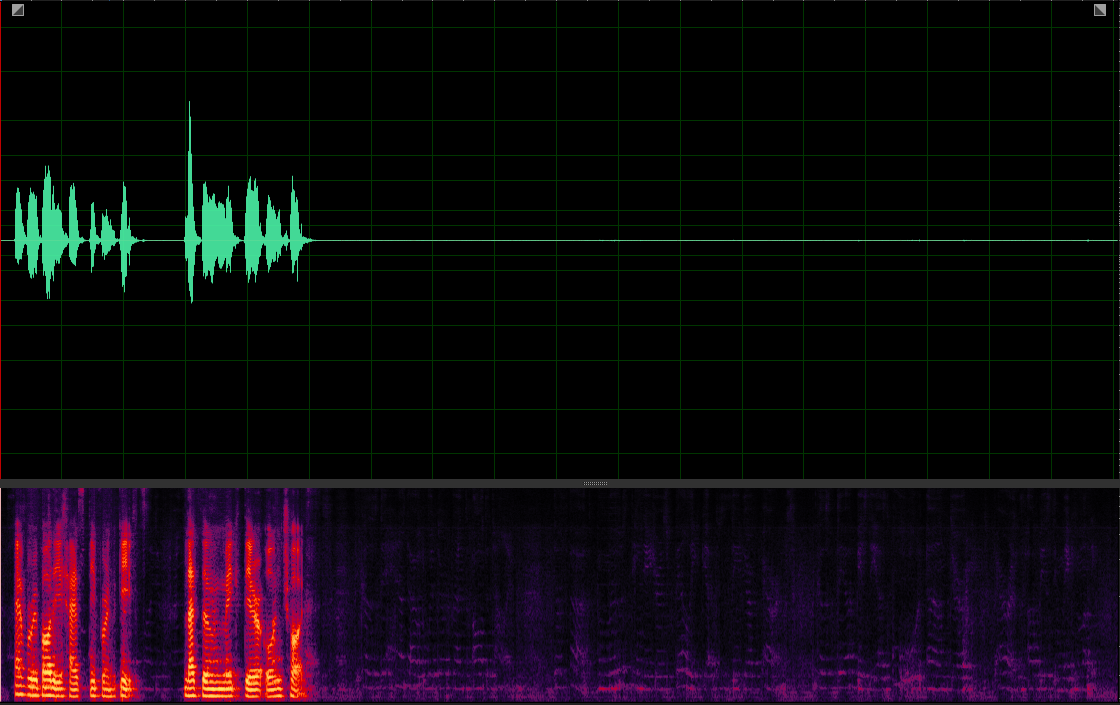
Our MuSS with BI-VP
(WER: 20%; SI-SDR: 17.42)
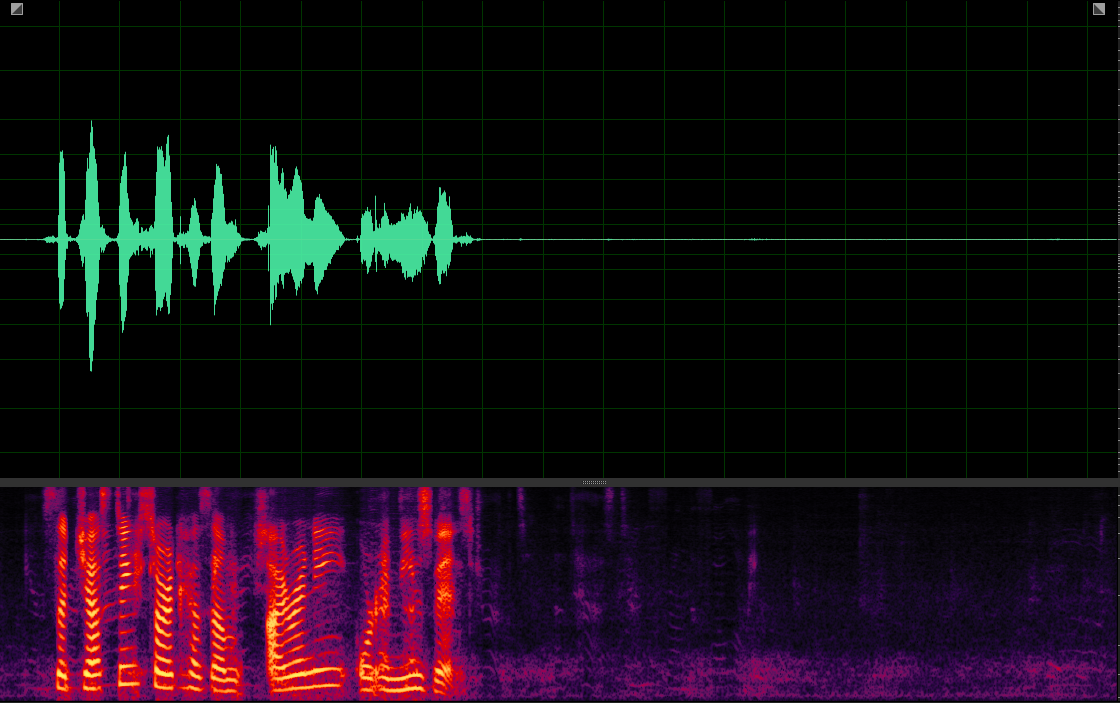
(WER: 6.25%; SI-SDR: 15.62)
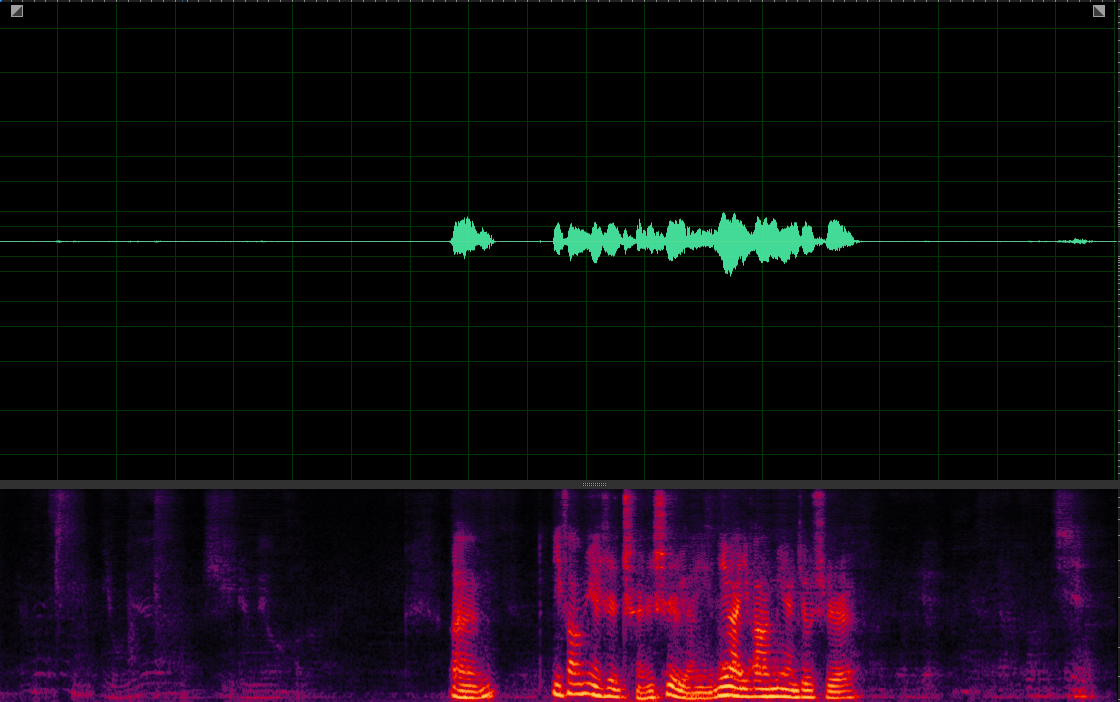
(WER: 0%; SI-SDR: 15.96)
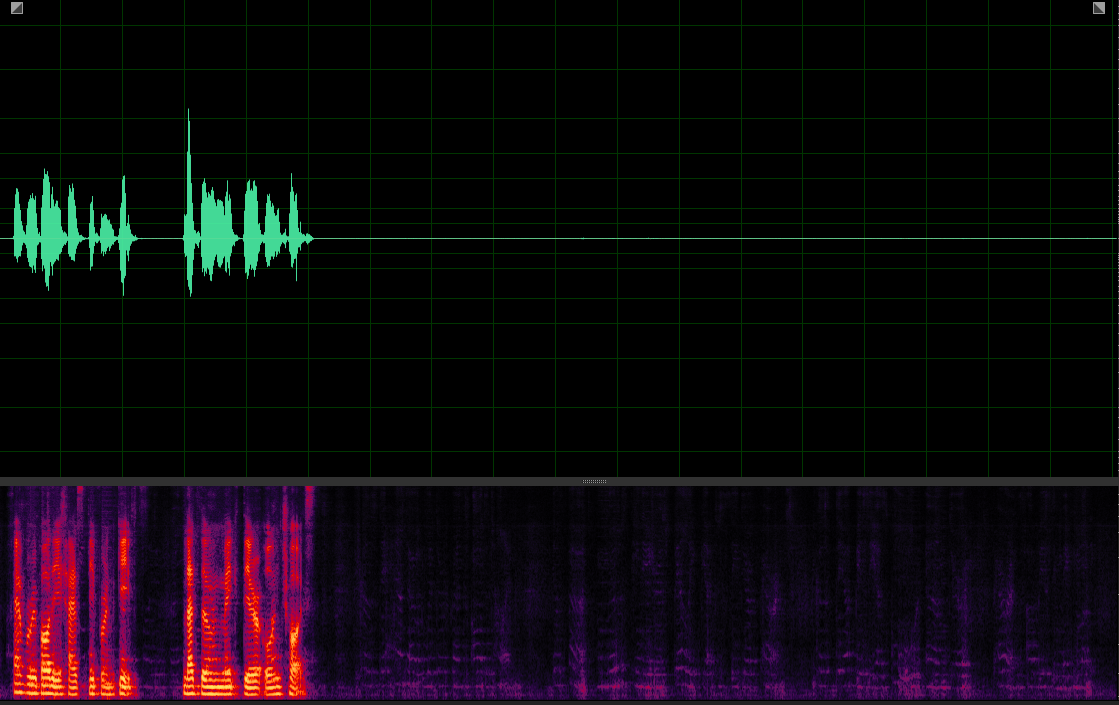
Our MuSS with VIS-VP
(WER: 0%; SI-SDR: 11.05)
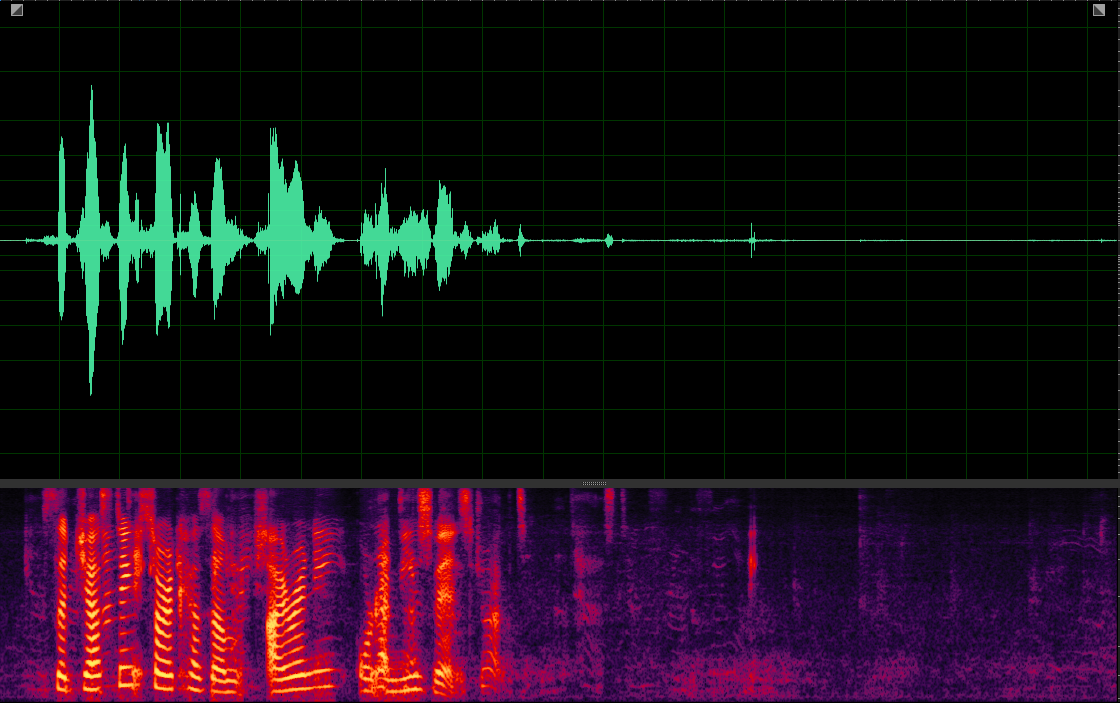
(WER: 56.25%; SI-SDR: 5.76)

(WER: 0%; SI-SDR: 11.22)
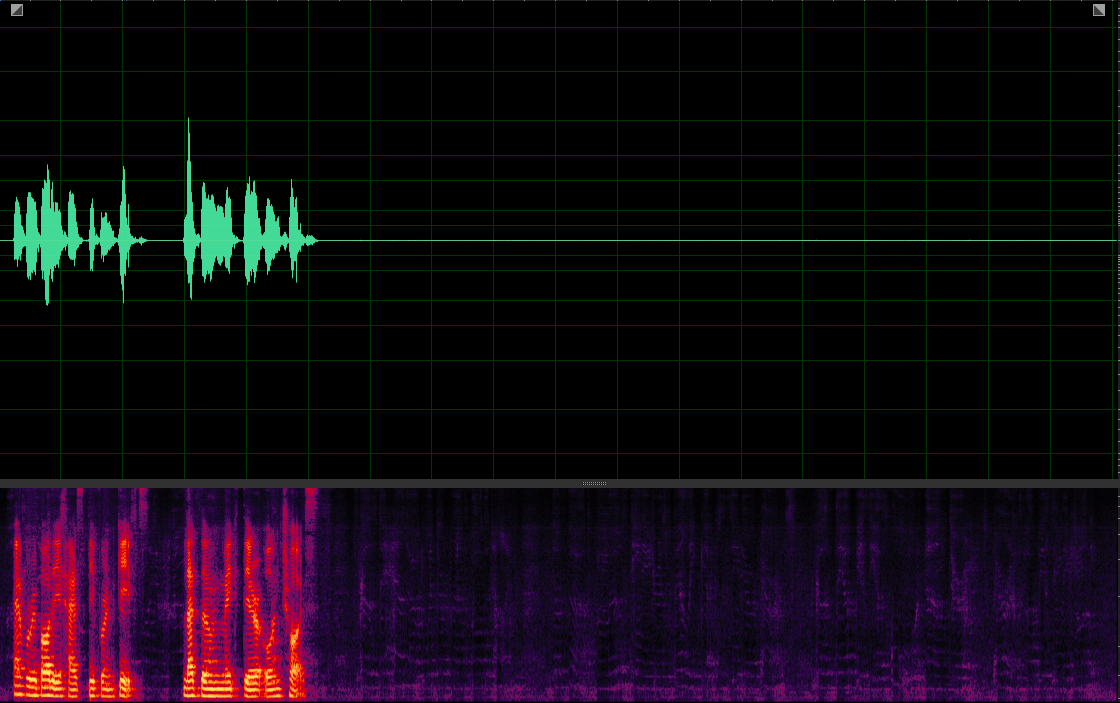
Our MuSS with VIS
(WER: 0%; SI-SDR: 11.61)
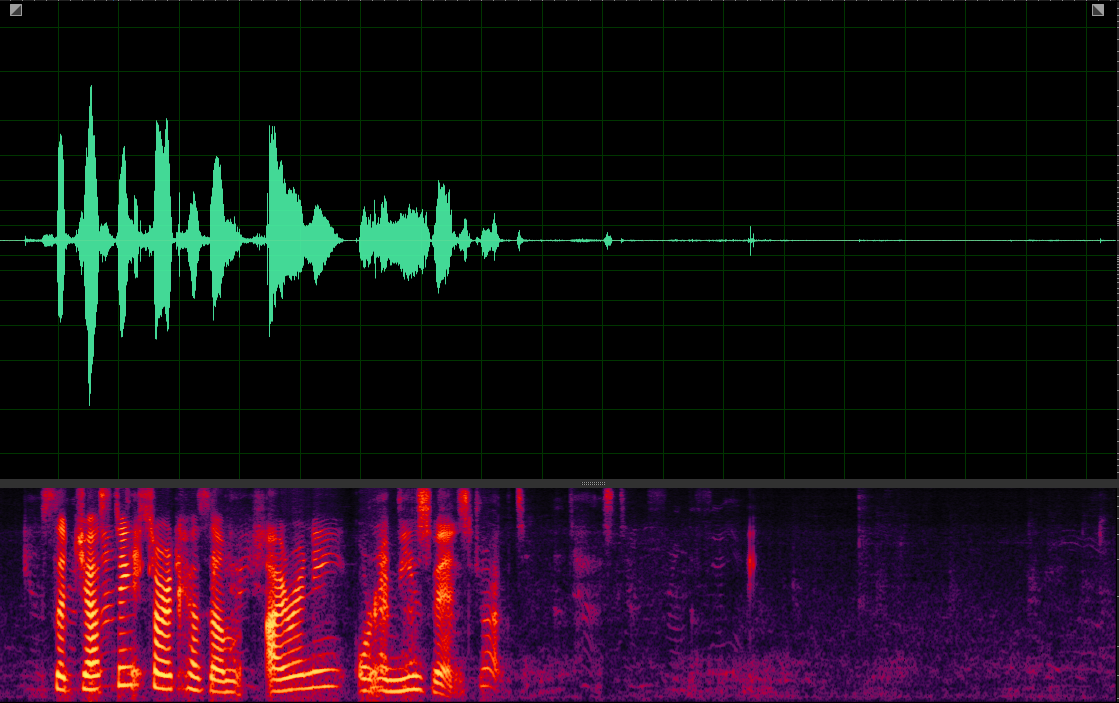
(WER: 56.25%; SI-SDR: 7.29)
(WER: 0%; SI-SDR: 11.33)
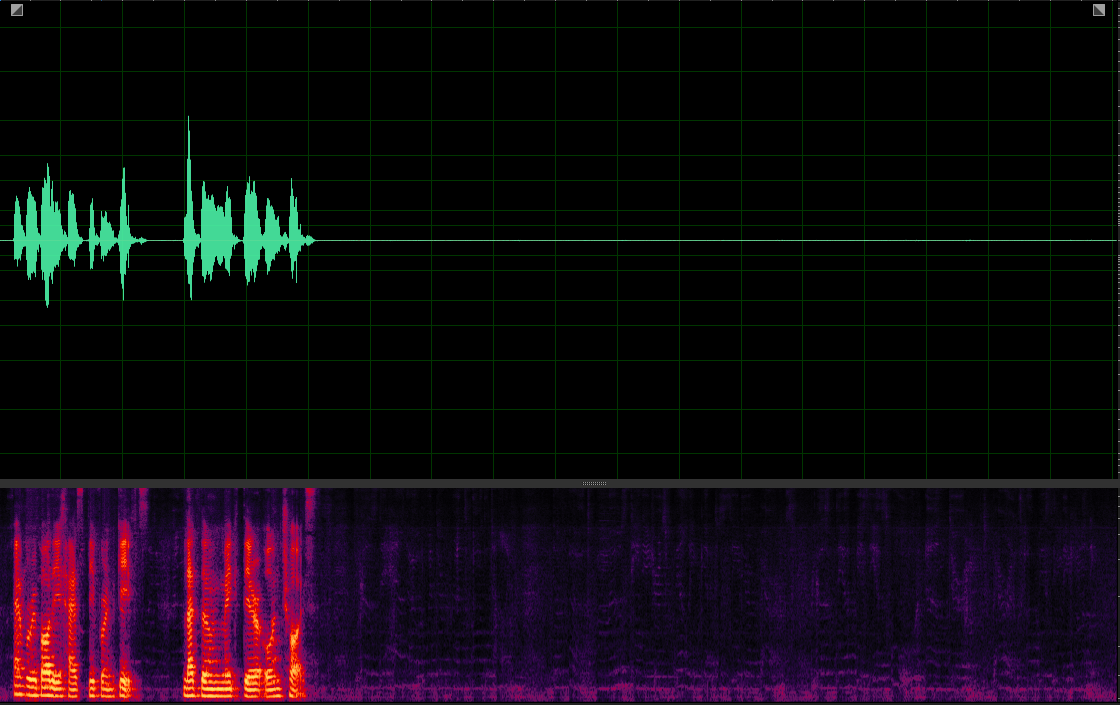
Our MuSS with VP
(WER: 40%; SI-SDR: 9.73)
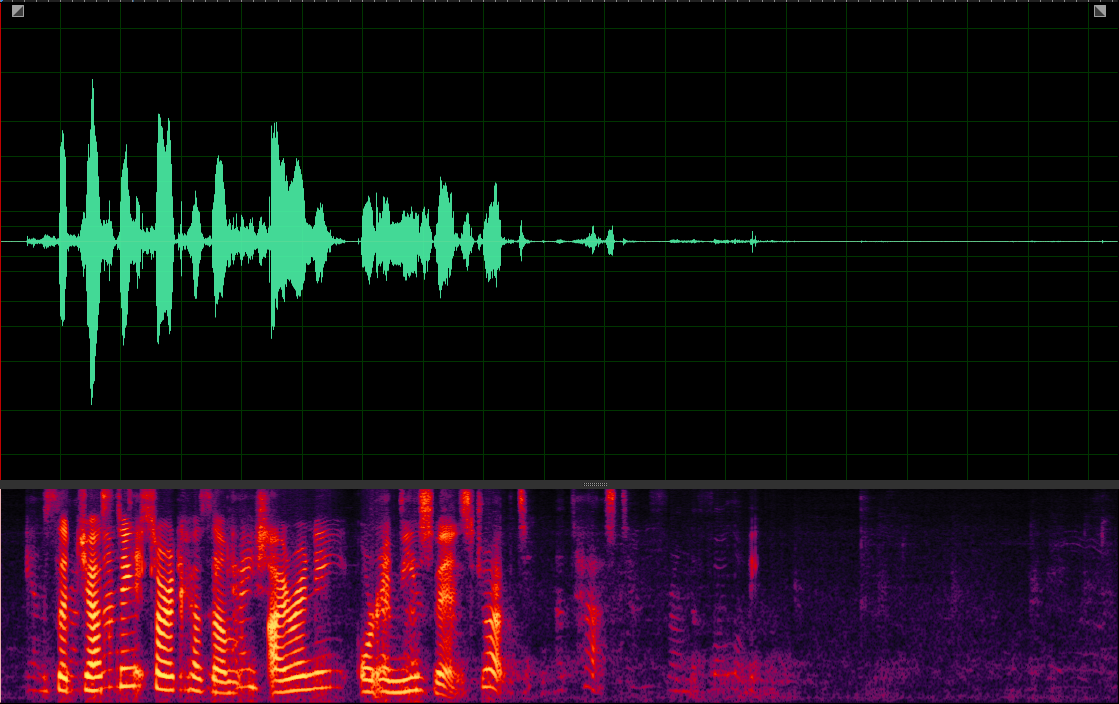
(WER: 56.25%; SI-SDR: 6.68)
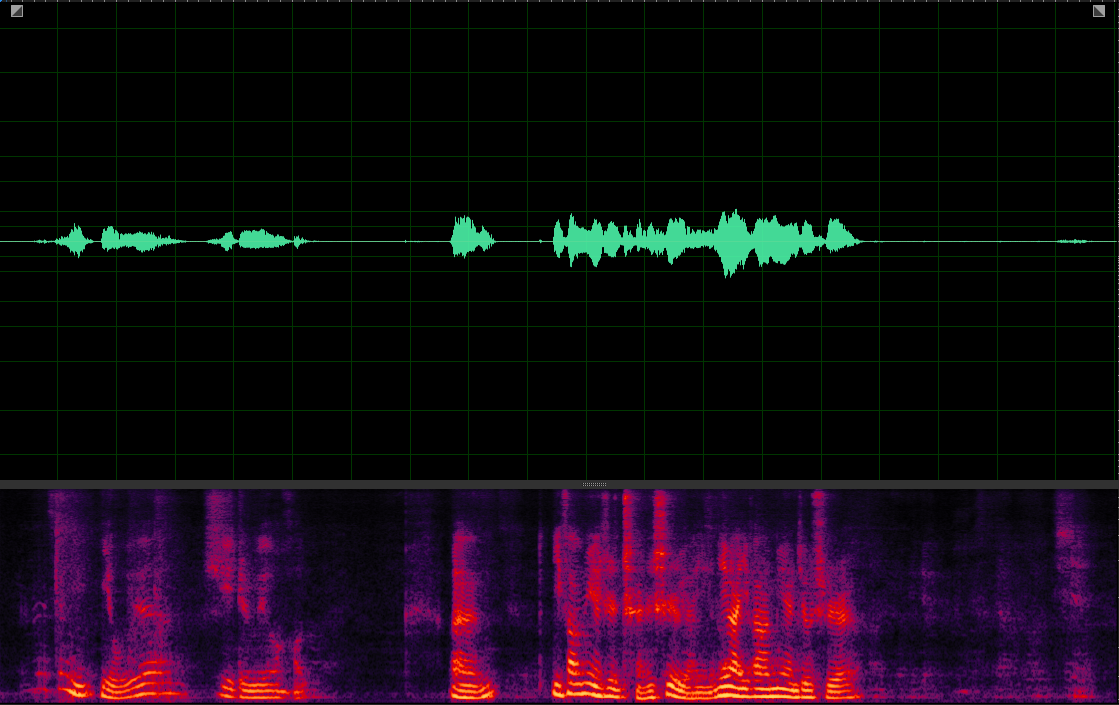
(WER: 0%; SI-SDR: 11.24)
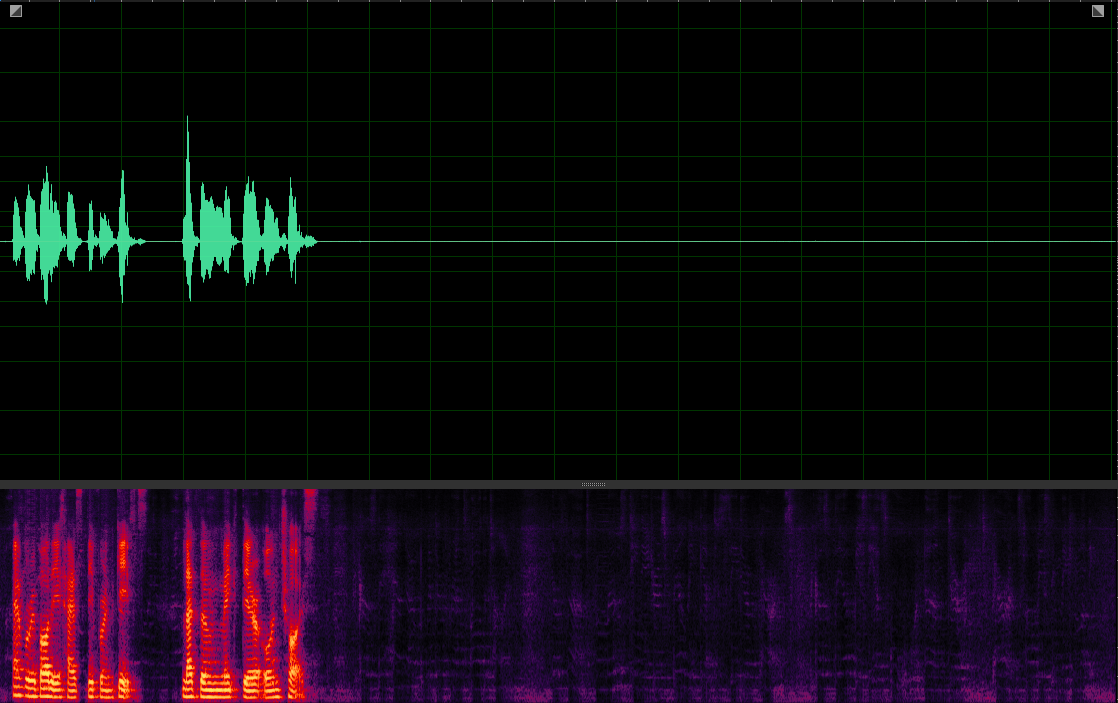
TasNet-MixIT (BI)
(WER: 0%; SI-SDR: 14.59)
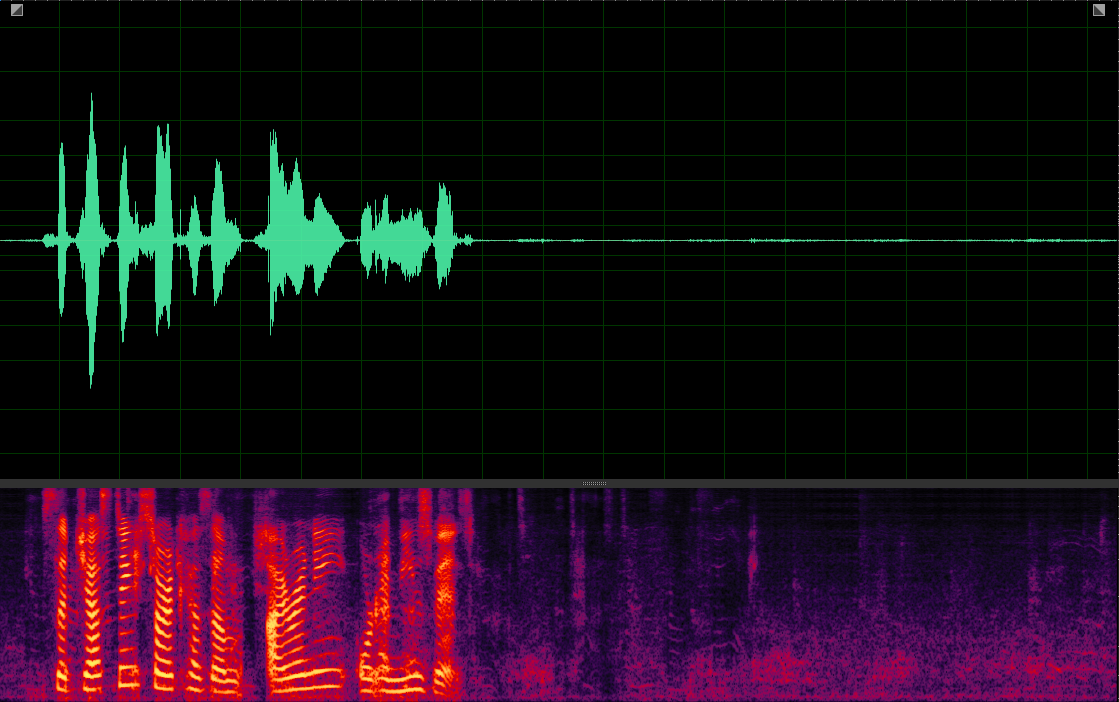
(WER: 6.25%; SI-SDR: 11.27)

(WER: 0%; SI-SDR: 11.32)
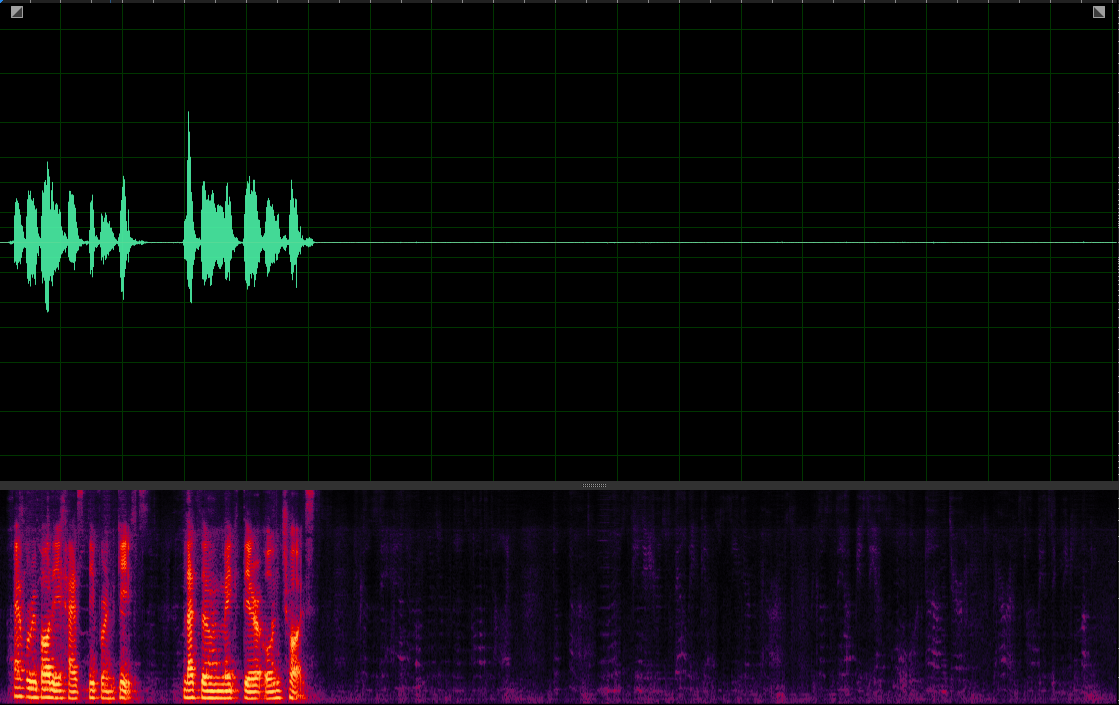
TasNet-MixIT
(WER: 40%; SI-SDR: 9.06)
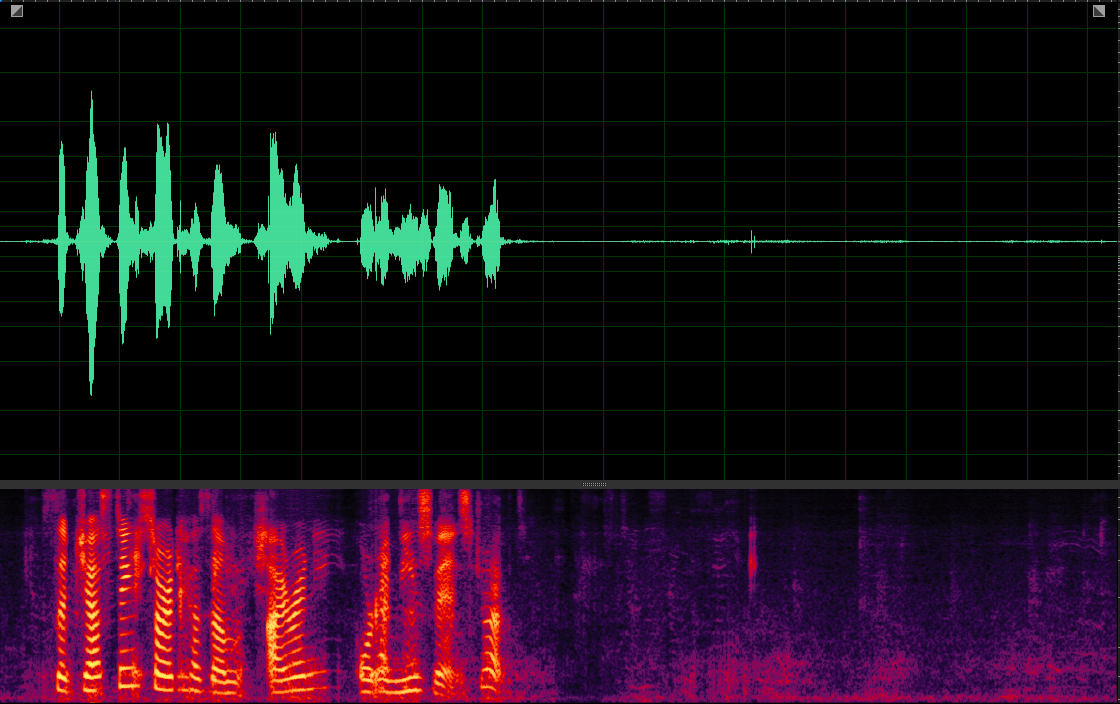
(WER: 56.25%; SI-SDR: 4.41)
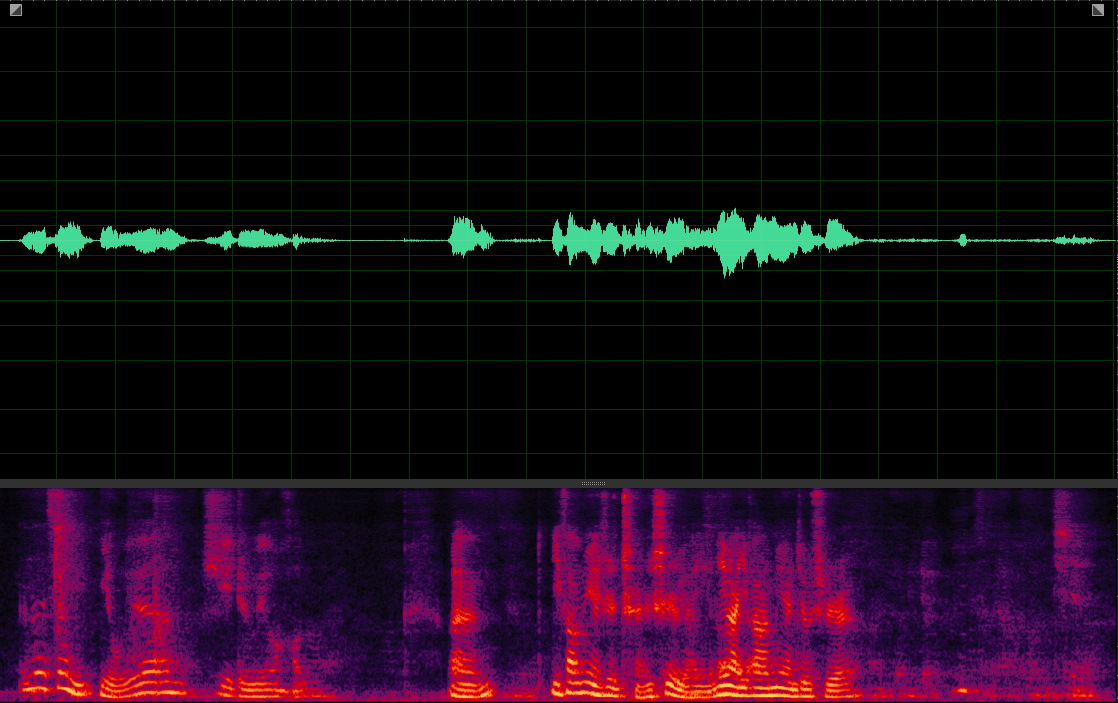
(WER: 0%; SI-SDR: 11.19)
Conformer-Large
(WER: 0%; SI-SDR: 11.36)

(WER: 0%; SI-SDR: 10.08)
(WER: 0%; SI-SDR: 9.94)
Conformer-Base
(WER: 40%; SI-SDR: 7.82)
(WER: 0%; SI-SDR: 9.37)
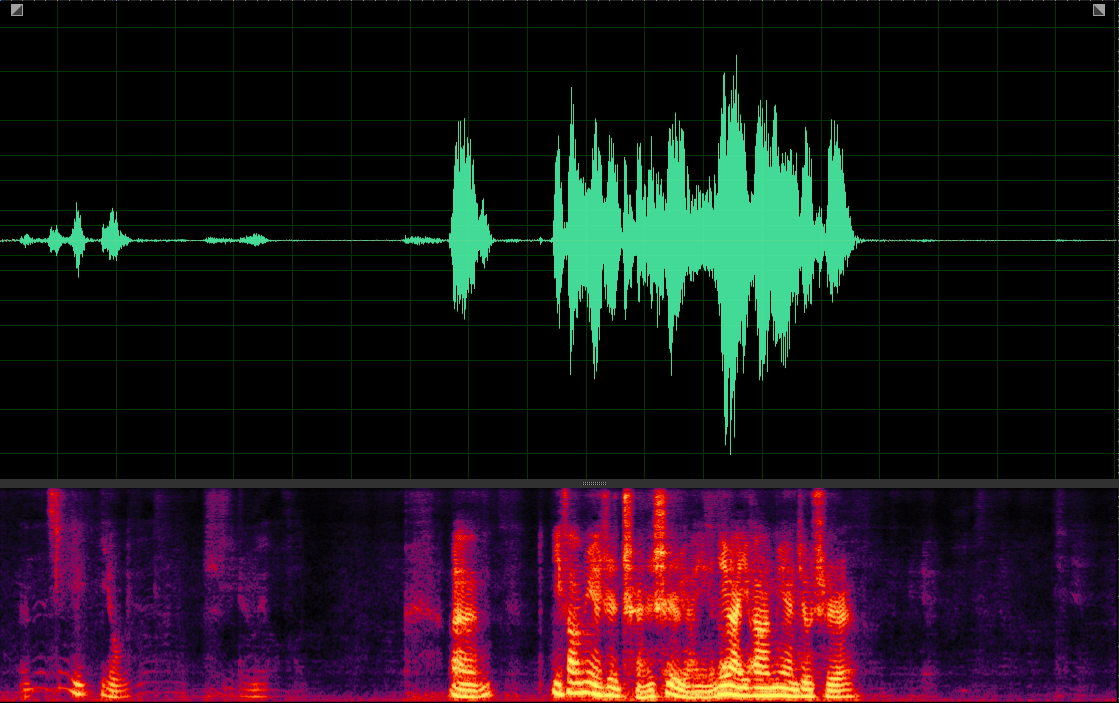
(WER: 0%; SI-SDR: 13.83)
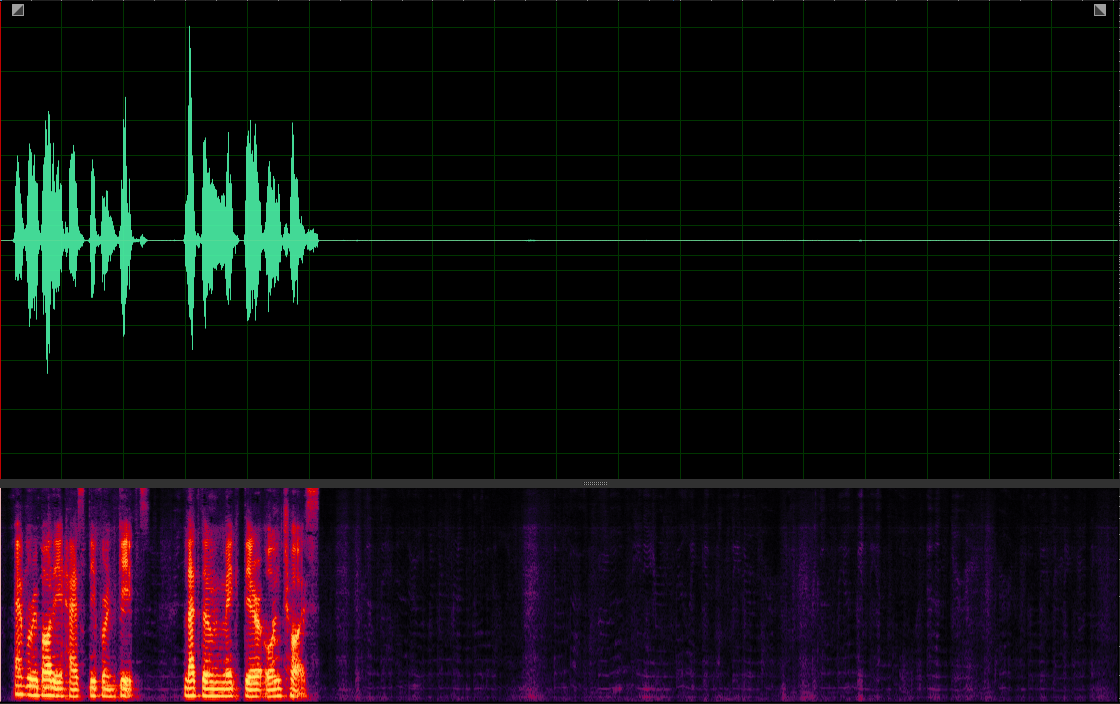
Sepformer
(WER: 20%; SI-SDR: 8.53)
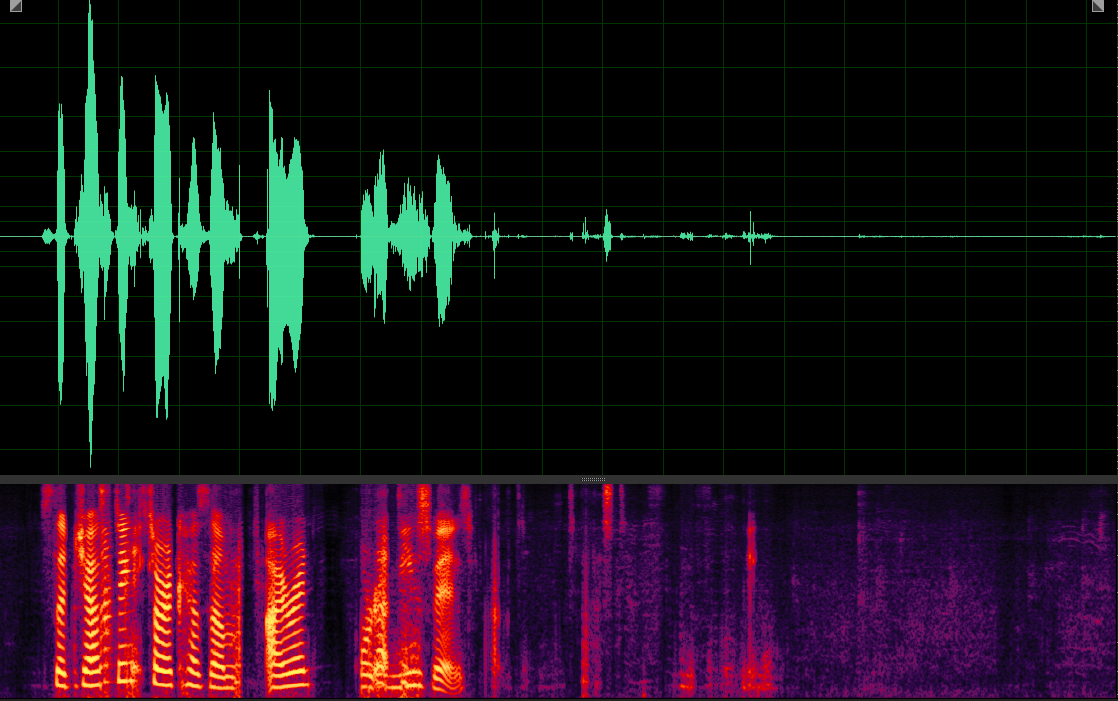
WER: 56.25%; SI-SDR: 1.5)
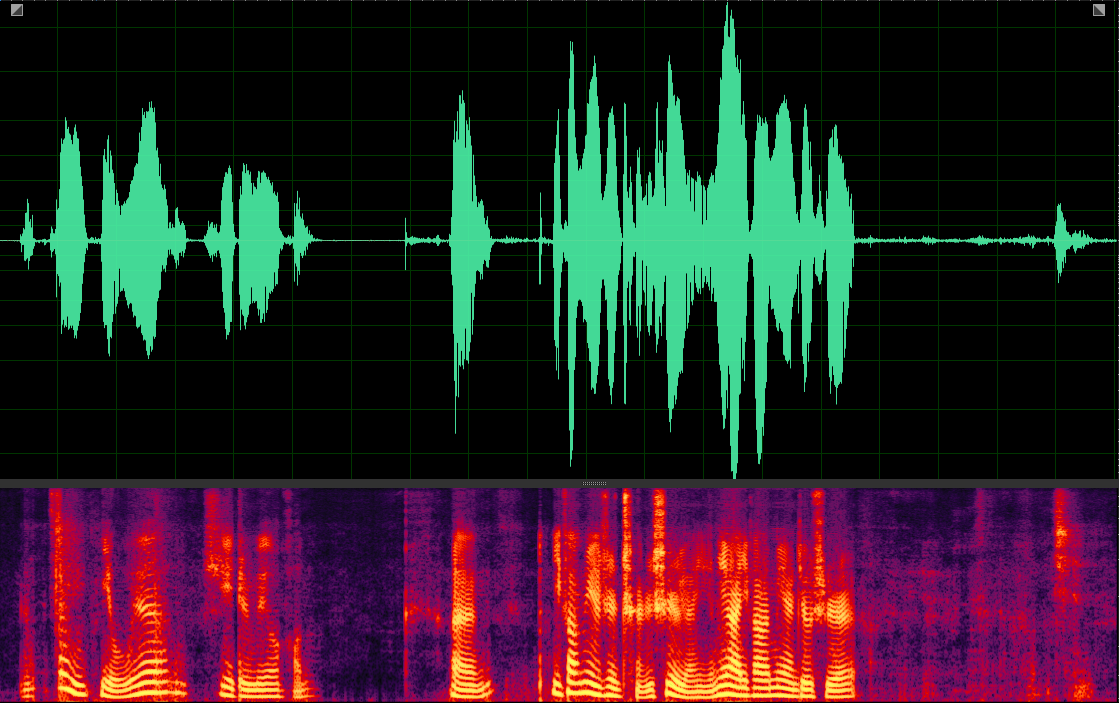
(WER: 0%; SI-SDR: 6.47)
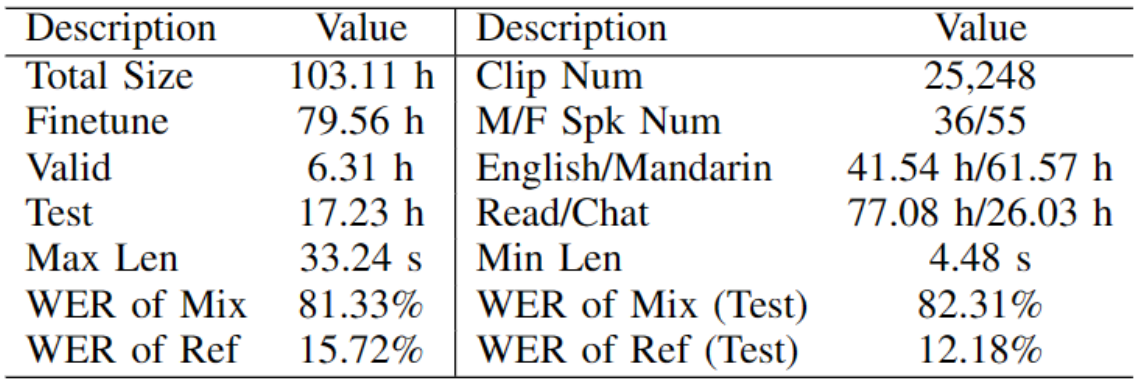
Dataset
RealMuSS
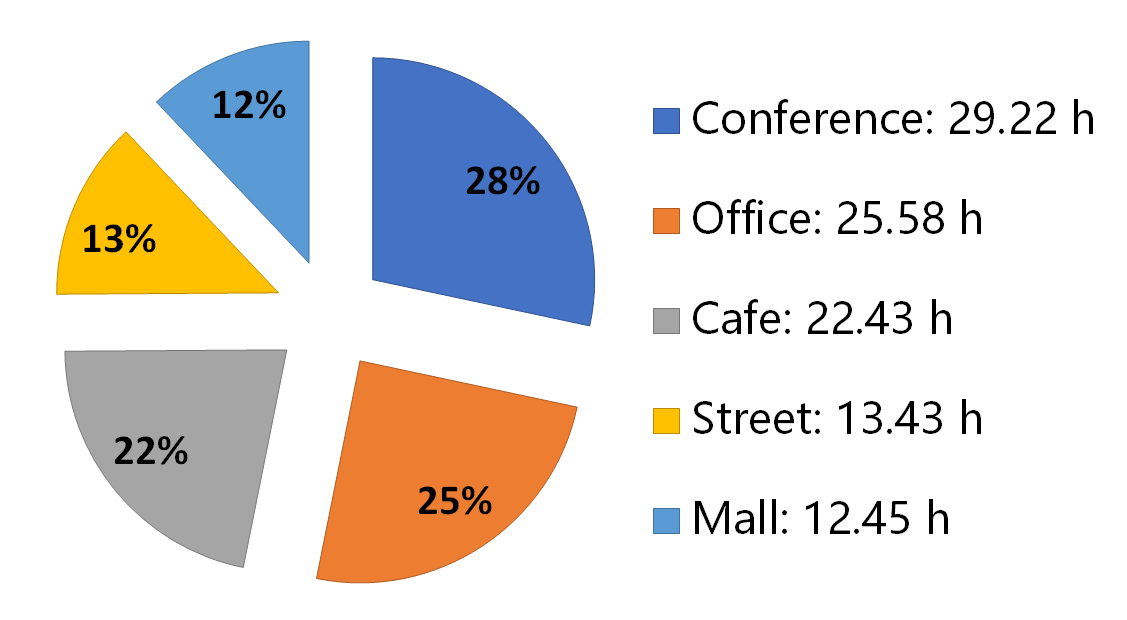
A 100+ hours Multi-modal English&Mandarin dataset for acoustic tuning and evaluation of speech separation.
The data is recorded in a variety of real scenarios.
The ratio of males and females, Mandarin and English, and the target person towards the device or any angle deviation is basically balanced when recording. Besides, the target person's reading and dialogue scenes accounted for 75% and 25% respectively. The summary of our RealMuSS dataset statistics is listed as follows, where M/F SPK NUM: Male/Female speaker number, MAX/MIN LEN: Maximum/Minimum length of the clips, WER OF MIX/REF: WER of the mixture/pseudo reference, H: Hour, S: Second.